

In this post, we talk about Unicode, about Strings, about how they sometimes become unexpectedly mangled when you pass them around the system and what we can do about it.
We’ll see some Chinese ideograms, peek into memory and display some nonsense on screen in the process.
VBA likes Unicode
Internally, VBA handles strings in Unicode encoded as UTF-16.
This means that each ‘character’ of the string uses at least a 16 bit WORD (2 bytes) of memory (not entirely true, but let’s keep it simple).
Below is the proof; it shows the memory content of a VBA string variable that contains the following sentence:
Chinese or the Sinitic language(s)
(汉语/漢語, pinyin: Hànyǔ; 中文, pinyin: Zhōngwén)
is the language spoken by the Han ChineseIf you see squares in place of the Chinese ideograms, then you are probably using an old version of Internet Explorer and do not have the Asian fonts installed: simply use the latest versions of Firefox or Chrome if you want to display them correctly (although you can still go through this post without seeing the exact glyphs).
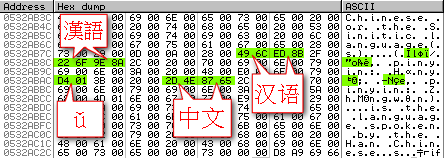
In memory, the layout of this VBA string is:
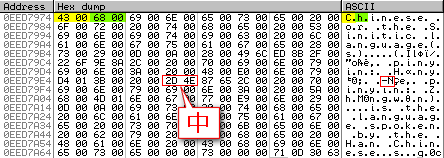
Each character of our string occupies 2 bytes: our first letter C whose hexadecimal code 0043 is located at address 0EED7974, then, 2 bytes later at address 0EED7976, we have our second character, h whose code is 0068 and so on.
Note that Windows is a Little Endian architecture, so the lowest significant byte 68 appears first in memory, followed by the most significant byte 00 at the next address.
On the right side, the map displays strange characters in place of the Chinese ones because the memory map interprets each byte as a simple ASCII character, but you can see for instance that the ideogram 中 is located at address 0EED79EA and that its code is 4E2D .
The character codes we see here are simply the ones that would be returned by the AscW() function in VBA (more or less).
VBA doesn’t always like Unicode
The thing though, is that VBA considers the outside world to be ANSI, where characters take (generally) 1 byte and strings must be interpreted according to a Code Page that translate the character code into a different visual representation depending on the encoding.
This means that if you are Greek, your system’s code page will be CP737 and you will see Ω (the capital letter Omega) if a string contains the hexadecimal code 97 whereas on a system set for western languages, including English, you will see ù: different representations of the exact same character code.
This nightmare of ANSI encoding made it very hard to pass around strings if you did not know which code page was associated with them. Even worse, this makes it very hard to display strings in multiple languages within the same application.
The Office VBE IDE editor is one such old beast: it only support the input and display of characters in your current system’s Code Page and it will simply display garbage or ? placeholders for any characters it can’t understand.
Fortunately, we’re not really living in an ANSI world any more. Since the days of Windows NT and Windows XP SP2, we’ve been able to use Unicode where each possible character, glyph, symbol has its own code point (things can be quite complicated in Unicode world as well, but that’s the topic for another post).
Unfortunately, VBA still inherits some old habits that just refuse to die: there are times when it will convert your nice Unicode strings to ANSI without telling you.
To make the situation worse, most of the VBA code on the Internet was written by English speakers at a time when Unicode was just being implemented (around 2000).
The result is that even Microsoft’s own examples and Knowledge Base articles still get things wrong and copying these examples blindly will probably make you, your customers and users very unhappy at some point.
To understand this unwanted legacy, and the solutions to avoid these problems, we’ll go through a concrete example.
Message in a box
Let’s study a simple case: display our previous message using the MessageBox Windows API.
The result we want to achieve is this:
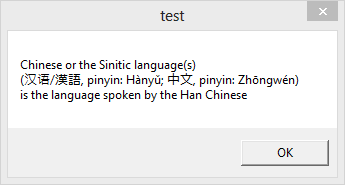
Note that in order to display Chinese ideograms, your system must have the proper fonts installed. If not, you’ll end up with little boxes where the glyphs should be displayed.
What we are talking about here is not limited to Asian languages though: it concerns all languages, including English if you ever include any symbols that’s outside of extended ASCII, like the Euro €, mathematical symbols, words in other alphabets like Greek, phonetics, accents, even Emoji (emoticon) symbols.
First attempt: MessageBoxA
OK, let’s go through the motions and try to use the MessageBox API.
Let’s first make a proper declaration that will work with all versions of Office:
#If VBA7 Then
Public Declare PtrSafe Function MessageBoxA Lib "user32" _
(ByVal hwnd As LongPtr, _
ByVal lpText As String, _
ByVal lpCaption As String, _
ByVal wType As Long) As Long
#Else
Public Declare Function MessageBoxA Lib "user32" _
(ByVal hwnd As Long, _
ByVal lpText As String, _
ByVal lpCaption As String, _
ByVal wType As Long) As Long
#End If
Now, let’s try to display the message box with our text.
Dim s As String
s = GetUnicodeString()
MessageBoxA 0, s, "test", 0The GetUnicodeString() function simply returns a string containing the text we want to display. It uses a function UnEscStr() from a previous article to convert escaped Unicode sequences into actual characters.
What we obtain is not what we expected:
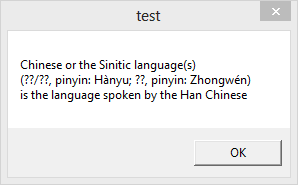
All Chinese characters have been replaced by ? placeholders.
Ok, so, if we look again at the signature of the function, we’re calling MessageBoxA. What does this A tacked at the end means?
The Windows API has generally 2 version of functions that handle strings: the old ANSI version, ending with a A, and the Unicode version, ending with a W, for Wide-Characters.
Our first tip is: whenever you see a WinAPI declaration for a function ending in
A, you should consider theWversion instead.
AvoidAWinAPI functions like the plague!
Get it right: MessageBoxW
So, now we know that we must use MessageBoxW for Unicode, the API documentation says so as well, so we must be on the right track.
Let’s declare the right API function then:
#If VBA7 Then
Public Declare PtrSafe Function MessageBoxW Lib "user32" _
(ByVal hwnd As LongPtr, _
ByVal lpText As String, _
ByVal lpCaption As String, _
ByVal wType As Long) As Long
#Else
Public Declare Function MessageBoxW Lib "user32" _
(ByVal hwnd As Long, _
ByVal lpText As String, _
ByVal lpCaption As String, _
ByVal wType As Long) As Long
#End IfThe only change is the W in the function name and we’ll call the Unicode version.
Let’s try to open that box again:
Dim s As String
s = GetUnicodeString()
MessageBoxW 0, s, "test", 0And this displays:
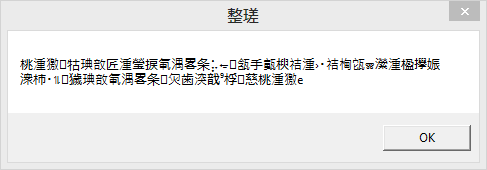
Oh dear.
Looks like Chinese, but it certainly isn’t what we expected. Here we’ve just got Mojibake, garbage due to incorrect processing of Unicode.
What could be wrong? We did pass a proper Unicode string, so what happened?
Well, VBA happened: whenever you pass a String as a parameter in a Declare statement, VBA will convert it to ANSI automatically.
Let me repeat this: when you see a
Declarestatement that usesAs Stringparameters, VBA will try to convert the string to ANSI and will likely irremediably damage the content of your string.
I’ll show you what happens by going back to our memory map. This is the content of memory before we call MessageBoxW:
This is the memory of the same string after the call to MessageBoxW:
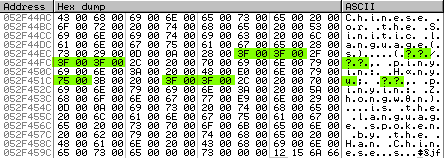
The string has been converted to ANSI, then converted back to Unicode to fit into 2-byte per character but in the process all high Unicode code points have been replaced by ? (whose code is 003F).
Note that the memory location of the string before and after the call are different. This is normal since the string was converted, so another one was allocated (sometimes they end-up occupying the same memory though it’s probably an optimisation of the interpreter).
In short:
Dim s As String
s = ChrW(&H4E2D)
' s now contains the 中 character '
MessageBoxW 0, s, "test", 0
' s now contains the ? character instead 'So our string was actually returned modified to us; we can’t even rely on VBA to keep our original string intact…
Get it right, use pointers!
So, it’s clear now, whenever VBA sees that you are passing a String in a Declare statement, it will silently convert that String to ANSI and mangle any characters that doesn’t work in the current Code Page set for the system.
To avoid that unwanted conversion, instead of declaring the parameters as String, we will declare pointers instead so that our final declaration will be:
#If VBA7 Then
Public Declare PtrSafe Function MessageBoxU Lib "user32" Alias "MessageBoxW" _
(ByVal hwnd As LongPtr, _
ByVal lpText As LongPtr, _
ByVal lpCaption As LongPtr, _
ByVal wType As Long) As Long
#Else
Public Declare Function MessageBoxU Lib "user32" Alias "MessageBoxW" _
(ByVal hwnd As Long, _
ByVal lpText As Long, _
ByVal lpCaption As Long, _
ByVal wType As Long) As Long
#End If
What we did here is simply define MessageBoxU as an alias for MessageBoxW which we know is the right API function.
Then we replaced the declaration for ByVal lpText As String and ByVal lpCaption As String, by pointers values: ByVal lpText As LongPtr and ByVal lpCaption As LongPtr.
From the point of view of the MessageBoxW function, in both instances it will receive a pointer, except that instead of a String, itwill receive the value of a LongPtr, which is functionally identical.
Now, when using our new MessageBoxU function, we also need to pass the value for the pointers to the strings explicitly:
Dim s As String
s = GetUnicodeString()
MessageBoxU 0, StrPtr(s), StrPtr("test"), 0The StrPtr() function has been part of VBA for a while now but it is still not documented. It simply return the memory address of the first character of a string as a LongPtr (or Long versions of Office older than 2010).
There are other functions to get the address of a variable: VarPtr() returns the memory address of the given variable while ObjPtr() returns the memory address of an object instance. We’ll have to talk more about those in another post.
So, now, the result:
Hurray! We did it! No unexpected conversion!
If you looked at the memory map, there would be nothing really interesting to see: the string would have stayed the same throughout the call and would be untouched: no conversion, no copy.
Not only did we manage to make call to API functions work, they are also faster because VBA doesn’t have the overhead of these silly Unicode-ANSI-Unicode conversions every time we use the API function.
What about the built-in VBA MsgBox?
VBA has had its own MsgBox function for a while, so why not use it?
Dim s As String
s = GetUnicodeString()
MsgBox s, , "test"Well, that’s why you should not:
Unfortunately, the VBA function MsgBox this is just a wrapper for the MessageBoxA API call, so no help there.
Parting words
This post has not been about Message boxes, although you will probably find my Enhanced Message Box replacement useful if that is what you are looking for.
The point of all this is simply to remember the following when involving Strings in Win API calls:
- Do not use the
Aversion of API calls, always use theWversion instead. - This is also relevant for some of the built-in VBA functions:
useChrW$()overChr()andAscW()overAsc(), bothWversion handle Unicode characters and are about 30% faster in my tests (see KB145745 for more information). - Check all code involving Strings with some real-world examples containing Unicode characters beyond the usual Extended ASCII set.
- VBA will mess-up and convert to ANSI all strings parameters in a
Declarestatement. - To avoid this mangling, use pointers instead of Strings in your declarations:
never declareAs Stringin an APIDeclarestatement. Always useByVal As LongPtrinstead and then useStrPtr()in your calls to pass the pointer to the actual string data. - Similarly, when passing a User-Defined-Type structure that contains Strings to a
Declarestatement parameter, declare the parameter asByVal As LongPtrand pass the UDT pointer withVarPtr(). - Remember that the VBE IDE cannot process and display Unicode, so don’t expect your
debug.printto display anything other than?for high code point characters.
Comments
Hi Renaud, Nice article. I read it trying to solve a problem but this is not quite our problem. We have a problem with the byte length of strings exceeding limits when we send the strings up to an Oracle database. In Oracle, you can use the Lengthb() function to return the byte length of a string. In VBA there seems to be no useful equivalent. LenB() does not appear to be useful. Example is this string a (Toy company) customer is trying to send from Excel to Oracle; RAPUNZEL DOLL – I AM A PRINCES Excel and VBA will claim this is 30 characters, which it is, but it is 32 bytes long thanks to the odd hyphen character. Are you aware of any way we can reliably determine the byte length of a character ? Thanks in advance, Bruce
Hi Bruce. I think you should open a question on StackOverflow where you will have more knowledgeable eyeballs than mine. In VBA, len() will return the length of the string in characters, but lenb() will return the number of bytes it uses. Since VBA uses UTF-16 encoding and uses 2 bytes for each character, lenb() should return at least 60 for your string, possibly 62 if that hyphen is outside the normal UTF-16 range and require a surrogate (in that case the hyphen would need 2 x UTF-16 codes, thus 4 bytes instead of just 2). Determining the byte length is already done for you: lenb() simply uses the byte count that is kept in the structure that hold the string data. The byte count is actually made of the 4 bytes that are just before the string starts in memeory. LenB() just reads that number. You do not say how you determined that the string was actually 32 byte long. If you are finding that the string is 32 byte long on the Oracle side, then maybe it was converted to UTF-8 where characters can be encoded with 1, 2, 3 or 4 bytes in extreme cases. In that case, your hyphen, if it is a special code point, may have been converted to 3 bytes instead of 1, explaining the 32 characters you find instead of 30. First you need to make sure you know what is the character encoding used by your oracle database. Then , if your oracle database is set to use UTF-8, you could first try to convert your strings to UTF-8 from VBA just to see how long they would be. You can use the StrConv$() VBA function for that, then count the number of bytes returned.
btw, just saw the Bruce Dog comment. I know it’s a year later but, the problem is likely caused by a trailing `vbCRLF` – this would account for the difference of the extra two bytes. Simple resolution is to Trim the string and then nix any leading or trailing `VbCR` or `vbLF`.
Hello Renaud, I read this article with some interest because of issues with users of Chinese Windows. Your remarks about using str Consts caught my attention. It seems that Chinese Windows converts all str Consts above chr(127) to Unicode, such that a normal str function will fail. I found alternate ways of resolving the issue, but wanted to say how impressed I was with this work. I believe I’ll find future use for the msgbox function. Therefore, I’m grateful for that. In the spirit of “not taking away if you don’t leave something behind”….. The following is a simple VBA routine that allows output to either a htm or txt file with correct display,. No API calls are required. Sub HTM_UNICODE() ' Simple util to show example output non ascii as Unicode ' Input params can easily be changed to File, Path, Msg ' ' Creates File HDR for Unicode to allow correct rendering ' Variables ' ----------------------------------------------- Dim bRET() As Byte 'bYTE aRRAY Dim sPATH$, sFILE$ 'PATH & FILE VARS Dim lCHR&, sRET$ 'BUILD VARS Dim sUC_HDR$, sHTM1$, sHTM2$ 'OUTPUT VARS ' ----------------------------------------------- Const s34$ = """" ' ----------------------------------------------- ' Notes for Const S34 ' Using a Const for Chr(34) makes code easier to read ' but to be honest, using label captions on hidden forms ' is prob more efficient from a coding labor point of view ' ----------------------------------------------- ' Set the Path & File ' ----------------------------------------------- sPATH = "H:\TEMP\" sFILE = "HTM_MSG.html" ' Set the header for Unicode File ' ----------------------------------------------- sUC_HDR = CHR(255) & CHR(254) ' Buid the the htm string ' ----------------------------------------------- GoSub SET_HTM ' Simple loop to grab some Greek Chrs ' ----------------------------------------------- For lCHR = &H3B1 To &H3C9 sRET = sRET & ChrW(lCHR) Next ' Punch the strings to the byte array ' ----------------------------------------------- bRET = StrConv(sUC_HDR, vbFromUnicode) & sHTM1 & sRET & sHTM2 ' ----------------------------------------------- ' Note: We only StrConv the leading Header! ' To out to a notepad txt file, don't include the htm vars, ' ---- and change the file name to .txt ' ----------------------------------------------- ' Kill any existing file ' ----------------------------------------------- Open sPATH & sFILE For Output As #1 Close #1 ' Note: the Open/Close is an alternative to Kill(Spath & sfile) ' (no error coding required) ' Write the file ' ----------------------------------------------- Open sPATH & sFILE For Binary As #1 Put #1, , bRET Close #1 ' At this point one can shell to the browser ' or open form with browser control ' Addition html, asp, java or vb script can restrict the ' browser open mode to create html dialog/msgbox type feedback.</p> Exit Sub SET_HTM: sHTM1 = "A message to you" & _ "" & _ "Hello:" sHTM2 = "Goodbye" Return End Sub Regards, Gary
Hi! Thank you for your tutorial. What about the built-in InputBox? It also has the same behaviour. How to make the InputBox process unicode strings correctly, like cyrillic or arabic? Kind regards, Gerald
I need to read in a text file which may have Polish, Norwegian or many other languages in it. The Input Line function performs a ‘translation’ such that the non ascii characters become mangled. Any hints on how to do this please? Many thanks Eoin
Comments are closed.